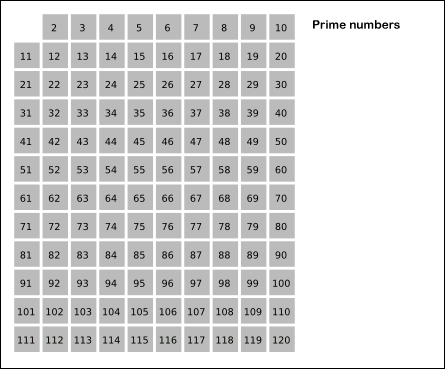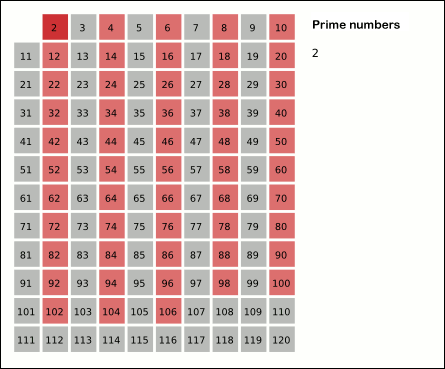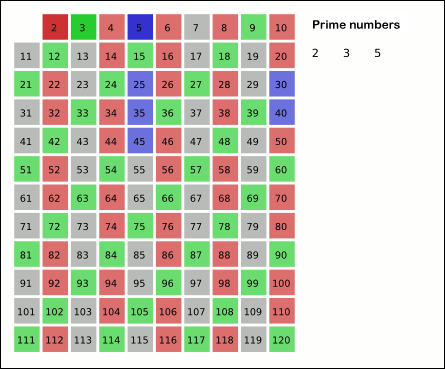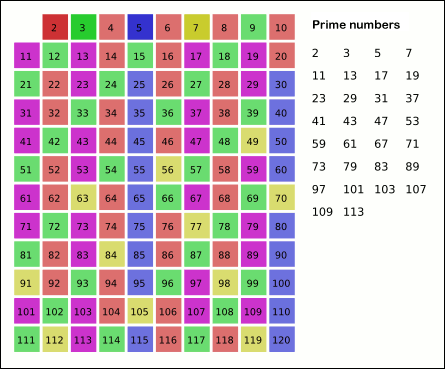
SIEVE OF ERATOSTHENES
Shubham Sand
Varun Shrivastav
Saket Thakare
PERFORMANCE TESTING
#include <chrono>
auto start = high_resolution_clock::now();
eratosthenes(n);
auto stop = high_resolution_clock::now();
auto duration = duration_cast<microseconds>(stop - start);
cout << duration.count();TIME ANALYSIS
for run in {1..100}
do
sum=$(($sum + $(./a.out 8000000) ))
done
echo "Avg time : $((sum / 100)) microseconds"AVERAGE TIME
int eratosthenes(int lastNumber)
{
int found = 0;
bool isPrime[lastNumber + 1];
// Initialize
for (int i = 0; i <= lastNumber; i++)
isPrime[i] = true;
// Find all non-primes
for (int i = 2; i * i <= lastNumber; i++)
if (isPrime[i])
for (int j = i * i; j <= lastNumber; j += i)
isPrime[j] = false;
// Count prime numbers
for (int i = 2; i <= lastNumber; i++)
if(isPrime[i])
found++;
return found;
}
BASE ALGORITHM
EXECUTION TIME
140195
in microseconds
2x Core
4x Core
133921
8x Core
133921
int eratosthenes(int lastNumber)
{
int found = 0;
// Initialize
char *isPrime = new char[lastNumber + 1];
for (int i = 0; i <= lastNumber; i++)
isPrime[i] = 1;
// Find all non-primes
for (int i = 2; i * i <= lastNumber; i++)
if (isPrime[i])
for (int j = i * i; j <= lastNumber; j += i)
isPrime[j] = 0;
// Count prime numbers
for (int i = 2; i <= lastNumber; i++)
found += isPrime[i];
delete[] isPrime;
return found;
}
IMPROVEMENT #1
EXECUTION TIME
128694
in microseconds
116906
116059
2x Core
4x Core
8x Core
~ 12.7% Gain
Replacing bool array with char array
int eratosthenes(int lastNumber)
{
int memorySize = (lastNumber - 1) / 2;
int found = lastNumber >= 2 ? 1 : 0;
char *isPrime = new char[memorySize + 1];
// Initialize
for (int i = 0; i <= memorySize; i++)
isPrime[i] = 1;
// Find all odd non-primes
for (int i = 3; i * i <= lastNumber; i += 2)
if (isPrime[i / 2])
for (int j = i * i; j <= lastNumber; j += 2 * i)
isPrime[j / 2] = 0;
// Count prime numbers
for (int i = 1; i <= memorySize; i++)
found += isPrime[i];
delete[] isPrime;
return found;
}
IMPROVEMENT #2
EXECUTION TIME
50573
in microseconds
50707
50390
2x Core
4x Core
8x Core
~ 60.7% Gain
Process only odd numbers
int eratosthenes(int lastNumber)
{
omp_set_num_threads(omp_get_num_procs());
const Number lastNumberSqrt = (int)sqrt((double)lastNumber);
Number memorySize = (lastNumber-1)/2;
char* isPrime = new char[memorySize+1];
int found = lastNumber >= 2 ? 1 : 0;
#pragma omp parallel for
for (Number i = 0; i <= memorySize; i++)
isPrime[i] = 1;
#pragma omp parallel for
for (Number i = 3; i <= lastNumberSqrt; i += 2)
if (isPrime[i/2])
for (Number j = i*i; j <= lastNumber; j += 2*i)
isPrime[j/2] = 0;
#pragma omp parallel for
for (Number i = 1; i <= memorySize; i++)
found += isPrime[i];
return found;
}
IMPROVEMENT #3
EXECUTION TIME
55968
in microseconds
83759
92897
2x Core
4x Core
8x Core
~ 53.6% Loss
Parallelizing the code
int eratosthenes(int lastNumber)
{
omp_set_num_threads(omp_get_num_procs());
const Number lastNumberSqrt = (int)sqrt((double)lastNumber);
Number memorySize = (lastNumber-1)/2;
char* isPrime = new char[memorySize+1];
int found = lastNumber >= 2 ? 1 : 0;
#pragma omp parallel for
for (Number i = 0; i <= memorySize; i++)
isPrime[i] = 1;
// find all odd non-primes
#pragma omp parallel for schedule(auto)
for (Number i = 3; i <= lastNumberSqrt; i += 2)
if (isPrime[i/2])
for (Number j = i*i; j <= lastNumber; j += 2*i)
isPrime[j/2] = 0;
#pragma omp parallel for
for (Number i = 1; i <= memorySize; i++)
found += isPrime[i];
return found;
}
IMPROVEMENT #4
EXECUTION TIME
56288
in microseconds
97930
102815
2x Core
4x Core
8x Core
~ 9.3% Loss
Scheduling the find-all for loop in auto mode
int eratosthenes(int lastNumber)
{
omp_set_num_threads(omp_get_num_procs());
const Number lastNumberSqrt = (int)sqrt((double)lastNumber);
Number memorySize = (lastNumber-1)/2;
char* isPrime = new char[memorySize+1];
int found = lastNumber >= 2 ? 1 : 0;
#pragma omp parallel for
for (Number i = 0; i <= memorySize; i++)
isPrime[i] = 1;
// find all odd non-primes
#pragma omp parallel for schedule(static)
for (Number i = 3; i <= lastNumberSqrt; i += 2)
if (isPrime[i/2])
for (Number j = i*i; j <= lastNumber; j += 2*i)
isPrime[j/2] = 0;
#pragma omp parallel for
for (Number i = 1; i <= memorySize; i++)
found += isPrime[i];
return found;
}
IMPROVEMENT #5
EXECUTION TIME
56520
in microseconds
98560
102232
2x Core
4x Core
8x Core
~ 0.173% Loss
Scheduling the find-all for loop in static mode
int eratosthenes(int lastNumber)
{
omp_set_num_threads(omp_get_num_procs());
const Number lastNumberSqrt = (int)sqrt((double)lastNumber);
Number memorySize = (lastNumber-1)/2;
char* isPrime = new char[memorySize+1];
int found = lastNumber >= 2 ? 1 : 0;
#pragma omp parallel for
for (Number i = 0; i <= memorySize; i++)
isPrime[i] = 1;
// find all odd non-primes
#pragma omp parallel for schedule(dynamic)
for (Number i = 3; i <= lastNumberSqrt; i += 2)
if (isPrime[i/2])
for (Number j = i*i; j <= lastNumber; j += 2*i)
isPrime[j/2] = 0;
#pragma omp parallel for
for (Number i = 1; i <= memorySize; i++)
found += isPrime[i];
return found;
}
IMPROVEMENT #6
EXECUTION TIME
48424
in microseconds
86776
88029
2x Core
4x Core
8x Core
~ 13.3% Gain
Scheduling the find-all for loop in dynamic mode
int eratosthenes(int lastNumber)
{
omp_set_num_threads(omp_get_num_procs());
const Number lastNumberSqrt = (int)sqrt((double)lastNumber);
Number memorySize = (lastNumber-1)/2;
char* isPrime = new char[memorySize+1];
int found = lastNumber >= 2 ? 1 : 0;
#pragma omp parallel for
for (Number i = 0; i <= memorySize; i++)
isPrime[i] = 1;
// find all odd non-primes
#pragma omp parallel for schedule(dynamic)
for (Number i = 3; i <= lastNumberSqrt; i += 2)
if (isPrime[i/2])
for (Number j = i*i; j <= lastNumber; j += 2*i)
isPrime[j/2] = 0;
#pragma omp parallel for reduction(+:found)
for (Number i = 1; i <= memorySize; i++)
found += isPrime[i];
return found;
}
IMPROVEMENT #7
EXECUTION TIME
34519
in microseconds
21600
14701
2x Core
4x Core
8x Core
~ 62.3% Gain
Adding reduction in prime count loop
int eratosthenes(int lastNumber, int sliceSize)
{
int found = 0;
for (int from = 2; from <= lastNumber; from += sliceSize)
{
int to = from + sliceSize;
if (to > lastNumber)
to = lastNumber;
found += eratosthenesOddSingleBlock(from, to);
}
return found;
}
int eratosthenesOddSingleBlock(const int from, const int to)
{
const int memorySize = (to - from + 1) / 2;
char* isPrime = new char[memorySize];
for (int i = 0; i < memorySize; i++)
isPrime[i] = 1;
for (int i = 3; i*i <= to; i+=2)
{
int minJ = ((from+i-1)/i)*i;
if (minJ < i*i)
minJ = i*i;
if ((minJ & 1) == 0)
minJ += i;
for (int j = minJ; j <= to; j += 2*i)
{
int index = j - from;
isPrime[index/2] = 0;
}
}
int found = 0;
for (int i = 0; i < memorySize; i++)
found += isPrime[i];
if (from <= 2)
found++;
delete[] isPrime;
return found;
}IMPROVEMENT #8
EXECUTION TIME
47679
in microseconds
47430
47383
2x Core
4x Core
8x Core
~ 6.02% Gain
Computing block-wise
int eratosthenes(int lastNumber, int sliceSize)
{
int found = 0;
#pragma omp parallel for reduction(+:found)
for (int from = 2; from <= lastNumber; from += sliceSize)
{
int to = from + sliceSize;
if (to > lastNumber)
to = lastNumber;
found += eratosthenesOddSingleBlock(from, to);
}
return found;
}IMPROVEMENT #9
EXECUTION TIME
33654
in microseconds
19692
14627
2x Core
4x Core
8x Core
~ 52.3% Gain
Parralizing block code
RESULTS
| CPU | BASE | FINAL | SPEED UP |
|---|---|---|---|
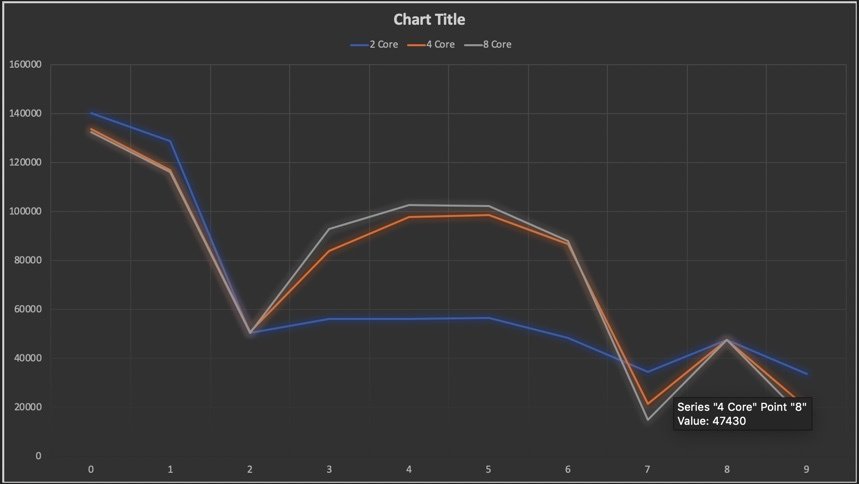
| x2 Core | 140,195 | 33,654 | 4.16x |
| x4 Core | 133,921 | 19,692 | 6.8x |
| x8 Core | 132,514 | 14,627 | 9.05x |
GRAPH